Немного милоты вам в это субботнее утро

Недавно завирусилась история о том, как кандидат вписал себе в резюме фиктивных два года опыта и прошел интервью на позицию в ИТ-компанию. Правда потом об этом узнали, и его вроде как уволили. Я не придал этому значения, пока мне не рассказали, что в одной онлайн-школе этому прям учат студентов, такая вот "гарантия трудоустройства". А на днях в одном из hr-чатов выложили фейковое резюме тестировщицы с 2 годами опыта, которая не смогла ответить ни на один технический вопрос.
В общем, весь этот треш оказался ближе, чем кажется. Не буду рассказывать, что обманывать нехорошо. Но я обратился за рекомендациями к Оле - HR в ИТ, карьерному консультанту и автору канала про карьеру, с которой мы трудоустроили уже ни один поток моих учеников.
Далее от ее лица.
Итак, последствия таких обманов могут быть разными:
(1) резюме могут закинуть по разным чатам и потом, чтобы найти работу, придется менять еще и фамилию (внутри одной сферы обычно тесно общаются и репутация дорога)
(2) в крупных компаниях есть службы безопасности, которые проверяют биографию еще до трудоустройства.
(у меня, кстати, был случай, когда клиентке отказали на последнем этапе из-за того, что данные из анкеты не совпали с реальностью)
(3) даже если все получилось, но в процессе работы информация вскрылась, могут и скорее всего уволят.
!(4) и что-то новенькое: hh.ru, на котором размещаются резюме, начал проверять точность информации и связываться с работодателями.
Поэтому поговорим о том, как можно привлечь внимание к себе, чтобы потом не уволили, как в этом случае:
(1) Начинать искать как можно раньше (когда изучена уже какая-то база), потому что то, что дают на курсах не всегда равно требованиям компаний. Чем больше смотрите вакансии и общаетесь, тем лучше понимаете, что нужно рынку.
(2) Использовать нетворкинг - знакомиться с людьми, которые работают в тех компаниях, куда вы хотите. Даже просто написать и попросить зарефералить. Теория с рукопожатиями тоже работает (у меня так много клиентов и знакомых нашли работу)
*кстати, консультант тут тоже обычно помогает и закидывает резюме по своим каналам (это, конечно, не гарантия успеха, но повышает конверсию)
(3) Резюме должно быть продумано до мелочей, из самого базового:
➡️ название должности должно соответствовать названиям вакансий, т.е не "специалист", а максимально конкретно;
➡️на первом месте должен быть опыт по той вакансии, на которую вы хотите, даже если это учебный опыт;
➡️ расписать подробно навыки, которые вы получили на обучении, лучше сразу с примерами из практики.
(4) Брать из предыдущего опыта все навыки, которые могут быть полезны. Смена направления — это не начинать с нуля, всегда есть переносимые навыки. Например, опыт ведения коммуникации и работа в команде, который есть у всех, и другие soft skills. Успех поиска 50/50 зависит от hard и soft skills.
(5) Использовать сопроводительные письма и писать вдумчивые отклики на позиции (спам-рассылка скорее всего не даст результата). А вот резюме + нормальное сопроводительное можно отправлять не только на hh, но и напрямую в компании, даже если вакансии нет, вас могут добавить в базу и написать позже.
*я всегда читаю, когда вижу, что человек постарался, а иногда даже даю обратную связь и помогаю скорректировать.
(6) Использовать разные источники поиска, в том числе рассматривать стажировки, после которых можно трудоустроиться (иногда это быстрее, чем искать вакансии).
Да, рынок очень поменялся за последние несколько лет, и все эти шаги объединяет активность и инициативность. Пробуйте разные гипотезы, потому что если не делать, то точно не получится. И пишите в комментариях, если нужен подробный разбор того, как правильно составлять резюме.
❕Сегодня хочу поговорить на очень спорную тему, я бы даже сказал философскую. Отчасти из-за нее, возникает очень много непонимания между коллегами, работающими в одном и том же (казалось бы) "АйТи", но почему-то имеющих очень разное представление о процессах разработки и о том, что каждая роль команды должна выполнять. Особенно это часто всплывает в моих постах на этом ресурсе, в комментариях - это такой хороший срез из разных уголков нашего отечественного IT.
И это большая тема для постов и для рассуждений. Но сегодня сосредоточимся на небольшой части этой темы, касающейся непосредственно системных аналитиков.
Давайте поговорим о том, какие есть подходы к написанию ТЗ и степени его проработки на примере описания тех же микросервисов\их методов.
❕Представим, что мы является системным аналитиком в команде и нам поставили задачу - реализовать личный кабинет пользователя.
Т.е. когда пользователь нажимает на какую-нибудь иконку профиля в приложении или там на кнопку "Профиль" - ему должна открываться экранная форма, в которой ему отрисовывается определенный набор полей и эти поля заполняются информацией. Также допустим, что у нас сам объект "Пользователь" уже есть в системе, атрибутивный состав понятен и нужно только реализовать процесс получения данных о пользователе на фронт по его идентификатору (ТЗ на фронт, на экранную форму и на интеграцию его с бэком опустим).
Какие есть варианты написания ТЗ для данной задачи?
1️⃣Самый минимальный уровень детализации. Это когда системный аналитик просто ставит задачу на разработку Джире (ну или в рамках небольшой страничке в конфлю\ворде, в зависимости от того, как принято) и в постановке этой задачи пишет что-то вроде "Требуется реализовать процесс получения данных о пользователе и передачу ее с бэка на фронт по REST-запросу. Со стороны фронта требуется создать новую экранную форму приложения - "Личный кабинет" или "Профиль пользователя". Со стороны бэка требуется реализовать новый метод, который будет использовать фронт для запроса информацию по пользователю (и, скорее всего, перечисляет набор полей, которые должны передаваться на фронт в формате "Фамилия", "Имя" и т.д.)". Усё
Я не утрирую - это один из вариантов реального "ТЗ" на эту задачу. Плюсом к этому может быть описан пользовательский сценарий в вольном формате или в формате UC (и то это будет в лучшем случае). Т.е. по сути в рамках такого процесса разработчик получает из полезной информации - только состав полей, передачу которых ему нужно реализовать по запросу с фронта, и то только их наименования.
2️⃣Вариант с немного лучшей детализацией. В этом формате системный аналитик уже пишет ТЗ в каком-либо формате, в рамках которого указывает, что: "Требуется реализовать новый метод GET /users/, указывает полноценно параметры, которые данный метод должен потреблять на вход и параметры, которые он должен отдавать на выходе." Плюс может описать, также как в предыдущем пункте, верхнеуровневый сценарий взаимодействия с этим методом.
Уже чуть лучше и чуть больше полезной информации для разработчика, правда?
3️⃣Вариант с достойной реализацией. Этот вариант обычно используется на большинстве проектов ФинТеховских и я считаю его достаточным для того, чтобы написать хорошее, качественное ТЗ и разгрузить разработчика так, чтобы он не думал о деталях реализации, хотя бы алгоритмических и системных (то, к чему нужно стремиться со стороны СА, имхо).
В рамках этого варианта будет всё из предыдущих + будет полностью описана логика работы данного метода, как бизнесовая, так и техническая. Будут описаны все корнер-кейсы, правила обработки ошибок, варианты того, что может вернуться в ответе (кроме успешного ответа, еще и все варианты негативных). Логика может быть описана или на уровне псевдокода или просто словами - конкретно это уже не имеет значимой роли, главное то - что эта логика пошагово и подробно описана.
Пример подобного описания я приводил ранее в своих постах. Я топлю всегда как минимум за этот вариант описания любых задач - что бэковых, что фронтовых, любых. Избавить разработчиков от лишней работы с точки зрения проработки алгоритмов и логики, если мы вполне это можем сделать сами - у них хватает работы и так, можете поверить.
4️⃣Более полноценный вариант придумать не могу =)
Плюсом к 3 пункту дополнительно описывается еще и swagger-спецификация микросервиса в целом и конкретных эндпоинтов в частности. Кроме того, что это просто удобно, наглядно и очень детально - эту спецификацию разработчики могут использовать, чтобы сконвертировать ее напрямую в готовый код с расписанными классами и эндпоинтами, останется "только" докрутить бизнес-логику и метод готов (Тут просьба поправить меня коллегам, которые более глубоко погружены в разработку - так ли это или есть еще какие-то бенефиты для разработчиков. Могу в этом предложении быть не прав, пишу исходя из того, как мне это объясняли).
Кроме этого, такой подход хорошо использовать в парадигме swagger-first, особенно когда у вас есть насыщенный и активный процесс кросс-командной разработки. Отдать другой команде сваггер аналитику куда проще и быстрее, чем отдать полноценное ТЗ на сервис - хотя бы просто по времени. А большего им и не нужно (потому что им пофиг на то, как работает ваш сервис внутри, главное понять, как вас вызывать и что вы вернете в ответе).
А если это все еще и использовать в связке с asciidoc-документацией, выкладывании ее в git- ммм, сказка просто. Как вспоминаю об этих процессах, наворачивается скупая слеза ностальгии - как же это было здорово! Жаль, что я встретил это ровно в одном проекте, а во всех последующих так и не смог продавить внедрение чего-то похожего.
И я вполне понимаю почему (например, очень удобно когда ты почти не тратишь время и ресурсы на написание глубокого ТЗ - достаточно пары фраз, а дальше нехай разработчик разбирается. И чем дольше пишешь в таком режиме, тем больше он тебя поглощает). Но кроме этого есть и множество других, о чем поговорим в следующий раз.
А с какими процессами и подходами работаете вы?
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-, хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
А ты программируешь себе сидишь

Продолжаем список тем и вопросов, ответы на которые нужно знать, чтобы пройти собеседование на позицию джуниора.
Еще небольшое предисловие - судя по комментариям к предыдущему посту, не все понимают, что не обязательно, что ВСЕ эти вопросы попадутся вам одновременно. Это наиболее вероятные вопросы, которые вам зададут ( по крайней мере актуально для ФинТех сферы). Ну и опять же, всё очень зависит от интервьюера, его опыта и тех целей, которые ему поставило руководство компании\проекта, на интервью.
Есть еще очень хороший подход к интервью, когда ты задаешь вопросы по каждой теме, и чем больше правильных ответов дает соискатель - тем глубже ты копаешь в эту тему, пока его знания по вопросу не иссякнут. Это позволяет не просто прогнать человека по заданным темам, которые нужны компании, но и в целом представить его уровень более детально (плюс так куда интересней для всех участников собеса).
Более техническая часть собеса:
Архитектурно-интеграционные вопросы:
Что такое клиент-серверная архитектура? Что такое тонкий и толстый клиент, чем они отличаются? (Тут никто не ждет прям уверенных технических знаний и деталей реализации того или иного подхода, но в общих чертах знать нужно).
Что такое HTTP? Какие основные методы HTTP вы знаете? Какие функции они выполняют? Расскажите про структуру HTTP-сообщений. (Если вы перечислите основные методы и скажете, что у сообщения есть заголовок, строка и тело - это уже, в целом, неплохо. Если знаете больше этого, вообще замечательно).
Что такое REST? Какие основные принципы у него есть? Какие методы есть в REST? В чем разница между GET и POST запросом?
В каких местах (четырех) мы можем передать атрибуты в запросе? (Path, Body, Query, Header).
Что вы знаете про концепцию CRUD?
Что такое идемпотентность? Какие методы являются идемпотентными?
Что такое синхронные и асинхронные интеграции? В чем между ними разницы? С помощью чего можно их реализовать?
Можно ли реализовать асинхронную интеграцию через REST? (Вряд ли этот вопрос будут задавать, если вы не ответите на предыдущие. Это скорее со звездочкой и не обязательный)
Что такое очередь сообщений? Как передаются сообщения через очередь? Какие очереди сообщений есть и в чем между ними разница? (Если расскажете про PUSH/PULL-стратегии - плюсик в карму обеспечен)
Что такое гарантированная доставка сообщений и какими механизмами ее можно обеспечить?
Какие вообще способы интеграции существуют? С какими из них приходилось работать? В чем их преимущества и недостатки? (Интеграция через обмен файлами, через общую БД, через веб-сервисы и обмен сообщениями)
Базы данных:
Что такое базы данных? Какими они бывают? С каким БД приходилось работать?
Что такое ER-диаграммы? Приходилось ли их проектировать?
На какой уровень оцениваете свой уровень владения SQL? С какими инструментами по работе с БД знакомы?
Ну тут могут конечно и про формы нормализации спросить, но уже лишнее, как по мне. Я обычно спрашиваю больше про опыт проектирования БД в целом. Приходилось ли проектировать базу в целом и под конкретные задачи в частности, каким образом это было сделано.
Различные задачки:
Тут вообще кто во что горазд в плане придумывания задач. В среднем, вам дадут умозрительное задание на проектирование какой-либо системы и попросят выделить основные классы этой системы (возможно, предварительно нужно будет собрать требования с интервьюера), спроектировать интеграцию между частями этой системы/интеграцию с внешними системами (плюс объяснить выбор технологии интеграции). Основной упор на ваши размышления, в основном именно в подобных вопросах можно понять уровень соискателя, потому что все остальные можно заучить. А тут проверяется именно понимание того, о чем вы рассказывали предыдущую часть собеседования.
Небольшие оффтопные вопросы:
Расскажите, что такое авторизация, аутентификация и идентификация? Чем они отличаются друг от друга? (почему-то один из самых любимых вопросов некоторых людей)
Чем верификация отличается от валидации?
Приходилось ли работать с JIRA\Confluence?
Конечно, так получается, что если вы знаете ответы на все эти вопросы, или больше 80-90%, то как будто бы вы уже не джун. Но чем лучше вы отвечаете, чем лучше вы соответственно подготовились - тем больше вам зададут вопросов (в нормальном интервью, а не шаблонном). Что очень сильно повысит ваши шансы получить оффер и выделиться среди других кандидатов.
Поэтому, конечно, можно, и зачастую нужно, пробовать собеседоваться, при наличии знаний, которые позволят ответить вам на половину из этих вопросов - шансы всё еще будут, плюс вы получите опыт прохождения собеседований (что само по себе очень важно) и определите те темы, про которые часто спрашивают, но в которых вы пока еще не сильны.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-,хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
Всем привет. Мой предыдущий пост, как мне кажется, получил огромный отклик. Его добавили в сохраненное только на Пикабу более 5000 человек, более 1500 репостов в ВК и более 750 комментариев, которые разворачивались в дискуссии. А также на меня подписалось около 300 человек. Тема, как выяснилось, оказалась актуальной, и интересной людям.
Я обещал ответить на вопросы, дать комментарии и поделиться ссылками и материалами, которые помогли именно мне. Обещал – отвечаю и делюсь :)
Ещё раз хочу подчеркнуть, всё что будет ниже - является сугубо моим личным мнением и опытом. Это не будет являться гайдом «как войти в айти с двух ног за 3 месяца». Моё мнение + возможно, рекомендации. Я могу быть где-то не прав, буду рад если более опытные коллеги меня поправят.
Курсы
Весь мой негатив в сторону курсов был направлен на распиаренные и разрекламированные курсы на всем известных площадках. Те самые, которые пестрят лозунгами «Легче всего попасть в IT через тестирование, мозгов не надо, 10 месяцев и мы тебя устроим на работу». Есть определенный процент людей, которые успешно заканчивают такие курсы и находят работу, повторюсь, среди моих друзей и знакомых таких людей нет.
В самом начале пути я почти купил курс на ЯП за ~75к на системного аналитика. Но ознакомившись с программой курса я понял, что 70% из предлагаемого я уже знаю и делал, остальные 30% смогу добить в бесплатных источниках. Около двух месяцев мне настырно названивали и пытались впарить (другого слова не подобрал) этот курс. Агрессивный маркетинг только усилил мою негативную позицию.
Я ничего не имею против платных и полезных курсов, и мне не жалко заплатить за повышение своей квалификации, часть таких курсов также оплачивает мой работодатель. Но они не имеют ничего общего с ЯП, ГБ и прочими. Рекламировать платные узконаправленные курсы не вижу смысла, когда они вам понадобятся – вас или на работе отправят учиться или вы уже сами будете знать чему и где вы хотите подучиться.
Образование.
Высшее образование (ВО) по моему мнению не является обязательным фактором при устройстве на работу, за исключением, наверное, сферы информационной безопасности, госконтор, и личного желания отдельных личностей видеть кандидатов с ВО. Бизнесу нужно чтобы твои знания превращались в его деньги. Если ты сможешь сделать это без корочки – работодателя не будет волновать её наличие. Я знаю людей, которые с зарплатами от 200 до 400 работают в IT-блоках крупных банков и не имеют высшего образования.
Про качество образования можно много рассуждать, но все мои знакомые кто заканчивал профильные ВУЗы отмечали лишь то, что полученные знания им не пригодились. Всему, чему нужно было научиться – они научились на работе. У кого-то уже был диплом, кто-то специально пошел получать ВО для того, чтобы иметь возможность уехать на ПМЖ в другую страну.
Про то что ВО бесполезно, я не говорю. Некоторые работодатели более лояльно относятся к кандидатам с ВО. В Университетах мы учимся учиться и выполнять бестолковые задачи в сжатые сроки. Но поступать в ВУЗ и учиться там 5 лет только для того, чтобы сменить сферу деятельности на IT – сомнительная затея.
Материалы, книги, курсы и полезные ссылки
Теперь же, по просьбам подписавшихся на меня людей делюсь тем, что помогло именно мне. Это не реклама, не гайд, это мой личный опыт.
Для того чтобы погрузиться в мир единичек и ноликов, было бы очень полезно понять почему именно 1, почему именно 0, и как оно всё работает. В этом помогает разобраться книга Чарльза Петцольда «Код: Тайный язык информатики». Купил бумажное издание, прочитал 2 раза. Мне очень нравится. https://www.litres.ru/book/charlz-petcold/kod-taynyy-yazyk-informatiki-48447357/
Стоит обратить внимание на канал Kontur Academy. Половину курсов на канале я точно просмотрел. Есть как базовые вещи, так и продвинутые @konturacademy1485/
По сетям мне понравился курс Андрея Созыкина. На канале также каждый сможет найти для себя что-то полезное @AndreySozykin/playlists
Перечень ссылок на общие темы хотелось бы закончить одной из самых полезных для меня ссылок. Букварь по дизайну систем - https://github.com/donnemartin/system-design-primer . Там и про сети, и про балансировку, и про микросервисную архитектуру и еще про много чего полезного.
Я не владею английским на достаточно хорошем уровне, который позволял бы мне читать всю техническую документацию и статьи без переводчика, поэтому пользуюсь расширением для Chrome “DeepL”.
Программирование
Для начала нужно для себя понять, чем вам хотелось бы заниматься. Писать мобильные приложения? Игры? Делать сайты? От этого будет зависеть выбор первого языка. Я начал со Swift. Даже купил б/у макбук для этих целей.
Swift. Книга Василия Усова «SWIFT. Основы разработки приложений под iOS, iPad OS, MacOS» - https://www.litres.ru/book/vasiliy-usov/swift-osnovy-razrabotki-prilozheniy-pod-ios-ipados-i-macos-pd-24426226/
HTML, CSS, JavaScript. Мне понравился канал Богдана Станчука. Почему-то именно он вызвал у меня доверие. Прошел видеокурсы HTML – 3 часа, JS – 11 часов. Есть информация и про Git и про Docker и 10 часовой курс по Python. Да и в целом достаточно большая концентрация полезностей на одном канале @Bogdan_Stashchuk
Python. Прошел курс https://stepik.org/course/58852/promo .
Советы, которые мне давали опытные разработчики примерно были одинаковыми:
Практики должно быть больше, чем теории, не нужно пытаться всё сразу выучить
Стараться постепенно изучать и само программирование. ООП, алгоритмы и т.д.
Пет-проект обязателен. Не нужно писать калькулятор в качестве пет-проекта. Ваш проект должен быть полезным. Если это приложение для мобилок – напишите то, чем будете пользоваться сами или порекомендуете друзьям. Планировщик заданий, менеджер паролей, может быть даже интернет-магазин. По мере обучения вы будете дорабатывать и улучшать свой проект. Я до пет-проекта так и не дошел.
Тестирование
Чтобы поступить на курс по тестированию (о нём в конце) мне хватило книги Романа Савина «Тестирование ДОТ КОМ». Кто-то считает эту книгу достаточно сомнительной, но мне хватило. Плюс смотрел канал Лёши Маршала, там есть отдельный плейлист «Тестировщик с нуля» @leshamarshal/playlists . В целом, на ютубе достаточно много такого контента, не думаю, что когда вам будут рассказывать о базовых вещах информация будет кардинально различаться. Выбирайте того, кого вам будет непротивно слушать.
Одним из лучших бесплатных курсов для QA я считаю The 100-Year QA-Textbook https://mentorpiece.education/textbook/ Узнал о нём примерно через год после того как нашёл работу, прошел большую часть для интереса и расширения кругозора. Есть версия на русском, но она неполная, дополняется по мере перевода. Это полностью структурированная информация начиная с базы (сети, sql, linux, HTTP, REST, API) заканчивая техниками тест-дизайна и работой с Docker. Создатели этой книги где-то даже говорили, что «всю эту информацию можно брать и продавать на своих курсах, только указывайте автора». Не исключено, что на курсах за 100+ тысяч вы будете учиться именно по этой книге.
Аналитика
Так как я рассматривал только системную аналитику – книга Карла Виггерса и Джой Битти «Разработка требования к программному обеспечению» https://www.chitai-gorod.ru/product/razrabotka-trebovaniy-k-programmnomu-obespecheniyu-2427772
Просто были сохранены в закладках эти ссылки про BPMN и UML. Поиск информации на эти темы не должен у вас вызвать трудности.
Техническое писательство
Не сильно много информации в интернете на эту тему, выделить могу только Семёна Факторовича. Канал на ютуб @documentatio/streams
Платные курсы я пока не проходил, но планирую https://documentat.io/courses/advanced-techwriting/
Бесплатные курсы
Я сам заканчивал курс QA: https://team.cft.ru/start/school
Вам на выбор: JAVA, ML, Support, QA, Android, ИБ, Аналитика, автотестирование и другие курсы.
Лучших студентов принимают на работу. Перечень доступных городов ограничен, и зависит от направления. Но вы же можете в анкете указать город, который подходит?)
10 из 40 учеников нашли работу. Причем половина из них – в других компаниях и городах. Лично знаю нескольких разработчиков, закончивших эти курсы и получивших работу в других компаниях. И это было абсолютно бесплатно и супер полезно.
Знаю существуют подобные бесплатные школы и от ВК, и от OZON, и в Альфа-Банке что-то есть. Но я ничего про них не знаю, поэтому и рассказывать не буду.
Простыня текста, по-моему, получилась еще длиннее, чем в прошлый раз, что-то наверняка упустил, о чем-то забыл рассказать, а что-то рассказал, но криво. Мог бы еще поделиться положительным опытом в создании резюме, если это будет кому-то интересно. Если вы хотите, чтобы именно я ответил вам в комментариях, пожалуйста тегайте через @. В прошлый раз я заблудился в сотнях комментариев и, к сожалению, не всем смог ответить :(
Создайте уже свое сообщество "Любителей подкинуть говнеца" и делитесь там своими историями...И тех кто вошел в IT с собой заберите.
Схвачу, конечно. Но, ребзя. вошли в IT, сидите там молча. За*еБали, честное слово.
Добавлю от себя кой-чего, как человека, находящемся на среднем звене "пищевой цепочки", но с этим имеющего богатый опыт работы с новичками, как совсем юными, так и уже в виде состоявшихся на прошлых местах дядек (даже бывшие военные были).
Самое главное, но не самое первое, что должен сделать для себя падаван, - это изучить академисческую теорию. Да, сука, без нее ника и никуда, если вы, конечно же, хотите что-то там зарабатывать:
Если вы идете менеджеры, то тут общая литература - менеджмент проектов (но и разработку бы хорошо изучить хотя бы на уровне "чайника", дабы не возникало вопросов в стиле "Хули 4 дня на изменгение цвета кнопки?!".
Если идете в аналитики, то тут хорошо автор предыдущего поста описал, но аналитика бывает двух вариантов:
Аналитика данных - тут, да, БД учить, OLAP/OLTP, СУБД и тд. Хорошо бы еще теорию данных в целом подучить.
Аналитика проектов - это следующий этап развития PO/PM:
Бизнес-аналитка - вы думаете, как сделать систему лучше.
Системный анализ - вы думаете, как заставить системы лучше взаимодействовать.
Если идете в QA, то:
Есть ручное тестирование - с этого нужно начинать, т.к. это позволит въехать в область впринципе: кейзы, сценарии, уровни тестирования и тд.
Автотестирование - это уже разработка, ибо нужно писать код для автотестов разного уровня: функциональные, интеграционные, приемочные, и тд.
Есть еще целая сфера DevOps:
DBA - это специализация на конкретных БД, причем, не только на ее администрировании, но и на использовании, поэтому нужно не только знать саму СУБД, но и теории данных, SQL/noSQL нотации конкретной СУБД, механизмы отказоустойчивости и масштабирования.
Просто DevOps, которые раньше назывались "админами": тут нужно знать теории сетей и операционных систем, знать современные технологии базирования проектов: контейнеры, оркестраторы, CI/CD системы (для них, кстати, тоже нужен хотя бы один язык, часто: Питон или Ruby).
Т.н. "сетевики": персонал, специализирующийся на работе с сетями передачи данных. Тут, имхо, вряд ли можно попасть "после 30-ти".
Разработка. Тут нужно начинать с изучения компилируемых и интерпретируемых языков, их разницы. Почему-то сейчас считается, что "войти в Питон" или "войти во фронт" за полгода реально. Реально, на позицию стажера. А где вы видели позиции стажера? Я видел один раз в жизни. Поэтому нужно выбирать специализацию в ней развиваться, затарившись тонной литературы, начиная с теории данных, заканчивая, например, в случае C/C++ теорией компиляторов.
Бекенд. Это "прослойка" между системами хранения данных и фронтами (мобильным приложение, сайтом или другим бекендом). Тут - оболие всего и вся: РНР, Питон, Go, Rust, Ruby и тд. В обоих видах языков свои плюсы и минусы. Суть бека состоит в том, что нужно знать часто минимум два языка. Например: PHP + Go, Python + Rust и тд. Т.е. связка интерпретируемого и компилируемого языка.
Прикладная разработка. Тут выбор меньше: C/C++, .Net, может, что-то еще. Хотя современные приложения могут быть написаны и на Питоне.
ERP-разработка: 1С, SAP, Axapta и тд. Обычно в такие сферы приходят случайно. Никто в здравом уме "после 30-ти" не сунется в ту же SAP или 1С.
Game Dev. Тут все понятно: берете навыки, полученные ранее, в C++, например, и изучаете какой-нибудь Unreal Engine 4/5. Сложно, долго, но можно приятно устроиться. К сожалению, в Game Dev не зайти просто на знании языка, ибо нужны специализированные знания.
Embeded-разработка. Тут выбор еще меньше: в основном, только C/C++. Очень узкая, но очень хорошо оплачиваемая сфера. Более не скажу ничего.
AI-системы. Тут просто. Есть Питон с Keras/PyTorch, построенные на TensorFlow, и есть всякие интерпретации в других языках для использования. Тут - кроме разработки нужна еще, как минимум, линейная алгебра. НО! Это очень перспективная сфера, куда можно и "после 40" зайти.
SRE. Отдельная каста супер высокооплачиваемых инженеров. Попасть "после 30" и тд - невозможно, ибо нужен огромный опыт и знания во всех областях сразу.
Так вот, самое главное - нужно учить теорию. Параллельно ли, изначально ли - неважно. Без теории 3/4 перечисленного выше - просто закрыто будет. Остальная четверть ограничится уровнем стажера. Теория написания кода, теория данных, теория информации, теория сетей, комплияторов, тестирования, анализа данных, теория баз данных - огромная сфера знаний.
Готовы ли вы тратить тонную времени? Вам решать. Причем, нужно сразу понимать, что, даже изучите вы, например, пытясь "войти в разработку" книги "банды четырех", не гарантирует вам ни-че-го просто потому, что тем же "'эйчарам" нужны конкретные навыки использования конкретных инструментов, а все остальное - это остальное (это отдельная огромная тема противостояния "эйчаров" и специалистов).
Идеальный способ "вхождения в айти" - это найти ментора. Не курсы, не школы и тд, а конкретного человека, который будет помогать и направлять вас на этом ебучем дремучем пути к льготной ипотеке.
P.S. На моем личном опыте есть печальная статистика: чем страше человек есть, пытаясь "войти", тем хуже из него спец при прочих равных. К сожалению, это так.
В посте про "наставление" накидали кучу годноты + в телегу.
По всему этому я пройдусь, буду иногда постить об успехах.
Некоторые глянул мельком. Поэтому если там есть продукт-плейсмент - отпишите и я удалю. На первый взгляд очень даже хорошо. Искал с нуля т.к. лучше повторить, чем вспоминать и ошибиться.
Первое я уже успел попробовать (находил сам), прохожу в текущий момент.
Stepik - python для начинающих
Далее пойдут те, до которых я еще не дошел:
Лучшие бесплатные курсы по DevOps [2023]
Командная строка для разработчиков – cli-for-dev
Отдельно ютуб:
Python Kivy (разработка для мобильных устройств)
Python
Длинный нудный курс по Системному администрированию (азы)
Администрирование Windows Server
Ультра-позитивный Олег о python
Если что-то хотите предложить - пишите в комментарии.
UPD: даже в начале написал, что я не в курсе ни о какой рекламе на тех ресурсах. И первый же начал разводить вонь о том, что я продажный и сайт вообще мой. Ууух я конечно злой гений.
Предлагайте ваши варианты, что сами пробовали. Обязательно попробую.
UPD2: я без понятия почему "это" вылетело в горячие. Не бейте блин тапком.
Всем привет.
Небольшое предисловие. Я осознаю, что этим постом я вступаю на охрененно тонкий лёд. Если уж к моему предыдущему посту были претензии за то, что я посмел использовать HTTP 404, то уже интересно, какие комментарии последуют после выхода этого поста, в любом случае - you are welcome!
Но тут стоит уточнить, что все те подходы (разные), по которым мы проектируем сервисы - они разные как раз потому, что нет единых mandatory правил к архитектуре приложений, которым если не следуешь - твоя система ломается и больше никогда в жизни не заработает, даже если ты исправишь ее. Есть лишь РЕКОМЕНДАЦИИ, а их многие интерпретируют по-разному и это тоже нормально. Для кого-то свойственно не использовать коды ошибок вообще и передавать их в теле ответа с HTTP 200, для кого-то нет. Ни один из этих подходов не является не правильным.
И нет никаких технических ограничений в принципе. Ты можешь спокойно использовать метод GET для удаления объекта, если ты его так напишешь (не делайте так) или использовать метод PUT, вместо POST, для создания объекта (так уже можно, если понимаешь почему). Главное, чтобы ты понимал как эти тонкости реализации правильно применять. Если сомневаешься - используй методы по классике, хуже от этого он работать не будет.
Да, можно уже прям сейчас кидать тапками.
Теперь уже к основному телу сабжа. Сейчас расскажу про ряд лучших практик, которые можно применять. @VRock, ты как раз спрашивал по поводу конвенции о наименовании ресурсов, тут про это тоже будет.
1. Имя endpoint'а - это существительное, а не глагол. Это одна из самых распространенных ошибок, которые я когда либо встречал (и сам совершал, естественно). Например, было в моей практике и такое - POST /generateMultipleDocument.
Тут важно понимать, что метод - это уже глагол и еще раз дублировать его в наименовании эндпоинта не нужно.
В идеале, в данном варианте будет POST /documents
Не везде от этого можно избавиться, но в большинстве случаев всё-таки можно, если потратить время на придумыванием вариантов (опять же - по факту нейминг ни на что, кроме красоты и структурированности вашего проекта не влияет. А на сколько это важно - решать вам или вашей команде).
1.1. Используйте множественное число. В большинстве случаев, при проектировании методов, работающих с вашим ресурсом - эти методы будут работать не с единственный экземпляром этого ресурса, поэтому название эндпоинта должно быть во множественном числе.
Если же нужно указать, что из всего массива экземпляров ресурса вам нужно получить\обновить\удалить какой-то конкретный, то помещайте идентификатор этого ресурса в URL, передавая его в path.
Например, вот так:
/documents
/documents/
Вместо:
/document
/document/
1.2. Используйте "/" для обозначения иерархии и в принципе используйте вложенность ресурсов.
Например, если мы именуем наш ресурс, как users//playlists//songs - это значит у мы хотим работать со всеми песнями, конкретного плейлиста конкретного пользователя. И сразу понятна иерархичность этих ресурсов.
1.3. Не используйте "/" как закрывающий символ вашего URI.
Вариант users//playlists//songs сильно лучше, чем users//playlists//songs/
1.4. Используйте "-" для разделения составных слов.
Заглавные буквы использовать нельзя, поэтому привычный lowCamelCase нам не подойдет. Если писать всё слитно - очень не читабельно.
Поэтому вместо /applications//creditcardhistory, куда лучше использовать /applications//credit-card-history.
2. Не забывайте про версионирование микросервиса. Почти любой сервис с течением времени развивается и обрастает все большим количеством функций. Если сервис при создании получил версию 1.0.0, то при добавлении какой-нибудь логики в него, добавлении нового метода или полного рефакторинга - версия должна измениться.
Например:
host/v2/documents вместо host/v1/documents после внесения мажорной доработки.
Основные правила версионирования - в случае, если меняется логика незначительно, не добавляется/изменяется обязательность атрибутов, то инкрементируется минорная версия.
В случае если был полный или частичный рефакторинг, менялись обязательные параметры (например, добавлен новый атрибут, который является обязательным), возможно при добавлении нового метода (тут вопрос к разработчикам, в этом случае тоже мажорная версия повышается или т.к. это не влияет на работу подписантов то пофиг?) - инкрементируется мажорная версия.
В этом случае, все подписанты (системы, использующие ваш сервис) вашего микросервиса должны в обязательном порядке переехать на новую версию вашего микросервиса, иначе они не смогут взаимодействовать с ним. Например, если вы добавили обязательный атрибут, то они будут получать в ответ на каждый запрос ошибку, если не доработаются и не начнут его передавать, что приведет к полной поломке этого процесса.
Однако, это не всегда обязательно - в случае, если появляется такая мажорная доработка, но ваши подписанты не готовы дорабатываться одновременно с вами (причин этому может быть множество) - вы можете выкатить одновременно две версии микросервиса, v1 и v2 и поддерживать их обе. Те, кто доработался будут использовать v2, остальные предыдущую версию. Это несет неудобства и затраты, но в любом случае лучше, чем допускать неработоспособность интеграции. В дальнейшем, когда все ваши подписанты доработаются - поддержку предыдущей версии можно остановить.
Примечание: структура версионирования такова: первая цифра - это мажор, вторая цифра - это минор, третья цифра - это патч. Про первые две я уже сказал, а последняя используется только разработчиками. Насколько я понимаю, она повышается вообще каждый раз когда вносят изменения в сервис, но тут могу быть не прав.
3. Используйте пагинацию.
Отправка большого объема данных на фронт, в ответ на его запрос о получении информации по массиву каких-либо объектов, не самая лучшая идея. Как минимум, если вернуть ему тысячи объектов, лежащих в базе и попадающих под выборку - он столько все равно не отобразит, но очень задумается.
Поэтому принято выполнять пагинацию таких данных (от слова page - страница), т.е. возвращать ему часть всей коллекции в каждом запросе. Например - 15, 30, 50 элементов + информацию о текущем положении полученной информации в общей выборке. Почитать про это можно более подробно где-нибудь тут (первая попавшаяся ссылка, я не вчитывался, не реклама).
4. Используйте коды ответов HTTP правильно и эффективно.
Их достаточно много (https://developer.mozilla.org/ru/docs/Web/HTTP/Status) и их можно использовать по назначению. Все знать и использовать не обязательно, но вот примеры их использования
Использовать 201 "Created", вместо 200 "OK", в случае если вы в POST действительно создаете какой-то ресурс. Используется только в POST (ну и в PUT, в ряде частных случаев).
Использовать 204 "No Content", вместо 200 "OK" для DELETE. Это ответ на успешный запрос и он не будет возвращать тело, что и не нужно для данного метода.
Не забывайте использовать 401 "Unauthorized", 403 "Forbidden" и 404 "Not found" вместо безликого 400 "Bad Request", когда это уместно. Как правило 400 кодом пользуются когда нужно ответить на какую-то ошибку валидации или в случае возникновения бизнесовой ошибки, которую вы заранее можете предсказать (очень настоятельно рекомендую хотя бы дополнять код ответа еще и кодом бизнесовой ошибки в этом случае и желательно ее текстом (error.code и error.message соответственно).
Для валидации желательно тоже).
А для всего остального можно и специальные коды использовать.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Пришла пора поговорить за бекенд, а именно, за всеми старый "любимый" РНР и иже с ним (почему "иже с ним"?, потому что сейчас часто этот язык идет в паре с Golang).
Был недалече период необходимости прохождения собеседований. Были несколько интересных случаев, правда, конторы вряд ли известные широкой аудитории, поэтому называть не буду. Штатная разработка мне давно не интересна, поэтому я искал нечто выше, типа архитектора, techlead, либо, на край, teamlead. З/п разная, но я искал 400+ (да, "Знающие" скажут, что это мало для таких позиций - я в курсе).
Т.к. я не буду называть конторы, то выскажу лишь собирательные аспекты, которые для себя выявил.
Небольшие конторы, до 100 человек. Их проблема - они часто не знают точно, кто им нужен, и легко вместо вас, опытного и подготовленного человека могут взять просто того, кто интервьюверу внешне больше понравился. У меня было несколько отказов с формулировкой "Взяли по рекомендации".
Мне еще ниразу не попадались с их стороны серьезно подготовленные в техническом плане люди. Вас легко могут спросить, чем int8 от int32 отличается.
Средние конторы, до 1000 человек. Вот, тут бывают самые интересные собеседования. Тут и компетенция интервьювером бывает самой разной. Кто-то вас может гонять по типам данных и "что выведет скрипт?", а так же сдобрив это кодингом в стиле "отрефакторите код", кто-то может попросить вас проработать абстрактную архитектуру чего-то, поспрашивать про способы ускорения и оптимизации приложений (репликации, шардинг, балансинг, кеширование и тд). Не редко просят оптимизировать таблицу и запросы к ней.
Один раз я наткнулся на очень сильного интервьювера. Мы обсуждали не просто тонкости интепретатора, но и различные возмжные последствия от его нюансов, а так же способы диагностики и устранения неполадок сервисов и приложений в "боевом режиме". Различные другие аспекты языка, типа "настоящей" параллелизации выполнения приложения.
Большие конторы. Тут основная, имхо, проблема в том, что они четко знают (действительно знают), как собеседоваать junior-разрабов, но часто совершенно не понимают, как это делать с более серьезными позициями. Я считаю, что это выходит из-за сильной корреляции ответственности между сотрудниками: в таких конторах крайне редко бывают сотрудники с экспертизой, а чаще те, кто пришел и сидит на одном месте в одной области.
Обычно у них первый этап - это алгоритмы, и не стандартные, а те, которые выдуманы интервьювером, либо около него. Почти всегда задачи максимально абстрактные и содержат слова "бесконечное кольцо", "огромный файл", "бесконечная очередь" и тд. В 100% меня спрашивали про то, как считать сложность алгоритмов, и какая сложность будет у того или иного.
Я считаю это проблемой потому, что на практике не бывает ничего "бесконечного", особенно на позиции артихектора или techlead: у любой задачи есть в 100% случаем граничные условия, от которых зависит решение (в любой, даже np-полной задаче, решение меняется в зависимости от количества элементов). Года 3 назад я еще пытался доносить это до интервьюверов, но теперь просто кидаю ссылку на профиль leetcode, если начинается "алгоритмистика" - сильно время экономит.
Не редко бывают совершенно тупые задачи в стиле "сджойнить стопицот таблиц и наложить рекурсию в одном запросе" - опять же, протсо на знание ради знаний, что не практике вы никогда не примените.
Еще почему-то меня часто спрашивали под "подкапотное" устройство http/http2 протоколов, модель OSI (sic!) и чем UPD лучше/хуже TCP. Пару раз были вопросы про OLTP/OLAP механизмы, и чем одно лучше/хуже другого.
Честно говоря, я ниразу не проходил первый этап из-за своей неприязни к подобному (что человек может нагуглить за 1 минуту), поэтому что там дальше, я не знаю :) Может, что-то действительно стоящее и интересное.
Если подвести итог, то, имхо, маленькие и большие конторы на подобные позиции не особо интересуют ваши практические технические скилы, больше - как вы себя подадите (первый этап в больших конторах - это не про скилы).
И чутка про забугорные конторы. В них часто потенциально невысокий уровень экспертизы интервьювера усугубляется наличием потенциальных индусов и всяких AWS/Azure сервисов, которые сильно разгружают (не в финансовом плане, конечно же) конторы. Так что знание этих сервисов даже, если вы идете на простую разработку, обязательны. Каждая вторая контора обязательно даст вам тестовое задание, и не потому, что "вас таких за забором дофига", а просто так.
Английский - естественно. Часто говорят про минимум В2, но на практике нужен С1, не меньше: если вам говорят, что собеседование будет на аглицком, это значит, что там будет либо native, либо fluent speaker.
Будет огромным плюсом, если вы познакомитесь с компанией заранее и проработаете свою мотивацию не в стиле "свалить из РФ".
Вообще, при собеседовании в забугорные конторы крайне важны soft skills. На столько важны, что вы обязаны научиться улыбаться, если еще не умеете. Я сейчас говорю про конторы, где HR сидит в каком-нибудь Кипре или Испании, а не те, что нанимают аутсорс рекрутеров в РФ.
Почему-то до сих пор часто конторы из заграницы уверены, что даже на лидирующие позиции достаточно 4000-4500$/мес gross, если вы из РФ. С учетом того, сколько придется на налоги и комиссии отдать, это очень мало.
Всем привет.
UPD. Опять получился длиннопост с большим количеством текста в формате моих пояснений - простите, но не представляю как по-другому можно что-то объяснить, вроде стараюсь не графоманить.
В этом посте, наконец, приведу один из примеров того, как может быть написано техническое задание (кто-то может придраться, что это не ТЗ, а какой-то другой вид документа - да, возможно, но как-то сформировалась привычка для упрощения, что ТЗ - это любой документ, в котором описывается техническая постановка задачи, которую разработчик должен реализовать), в котором описываются требования к методу получения информации по конкретному объекту.
Шаблонов, на самом деле много и от команды к команде отличаются. Где-то СА просто пишут, что "метод должен получать объект User из базы Users и дальше отдавать его вызывающей стороне" - и это вся постановка. В каких-то командах упарываются и пишут ТЗ на микросервис целиком, в связке статьи в git в формате asciidoc + swagger (yes, I like it и отдельно про это тоже расскажу).
Но в большинстве случаев принято что-то среднее между этими крайностями - системному аналитику важно описать следующее:
То, какие данные метод получит на вход и правила валидации для них;
То, что метод должен сделать с этими данными, т.е. какую бизнес-логику выполнить;
То, что метод должен вернуть в ответ вызывающей стороне.
Допустим, нам нужно описать какой-нибудь метод, который получает любую бизнес-сущность по ее идентификатору.
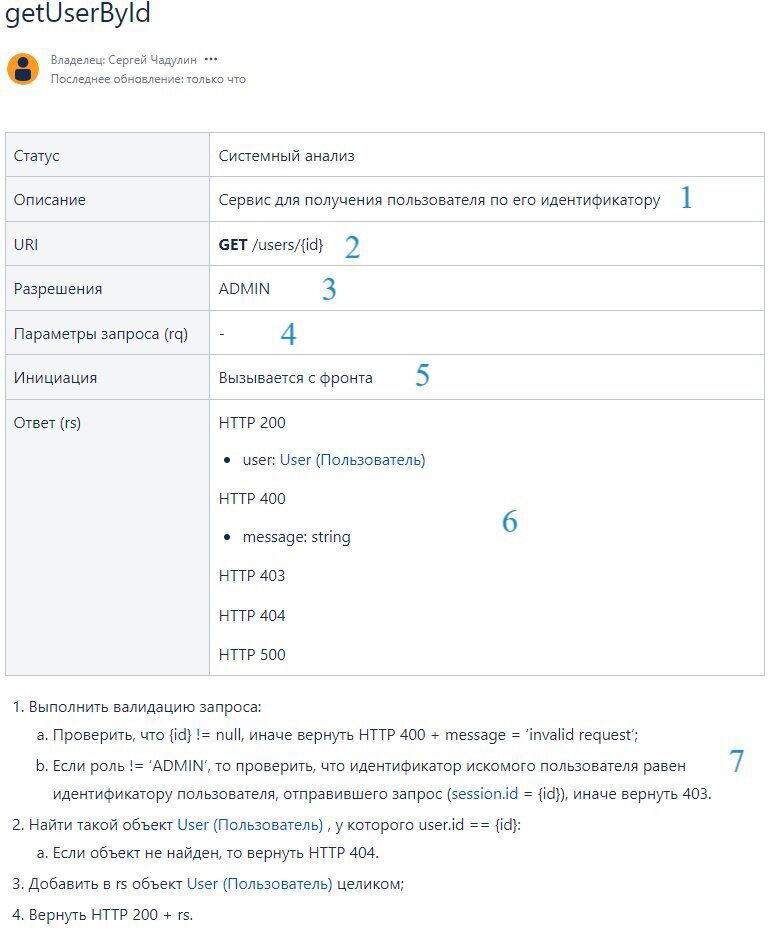
Один из шаблонов, позволяющий это описать выглядит так (к сожалению, приходится скриншотом, потому что пикабу не умеет в таблицы (или я не умею в таблицы на пикабу)):
Если кто хочет посмотреть "вживую" или попользовать шаблон - вот ссылка на страницу моего конфлю (вроде должна работать).
Теперь по шагам:
Описание метода. Что он делает, для чего предназначен. Можно описать что-то конкретное, если сервис работает как-то специфично, такую краткую выжимку, что сторонним людям не приходилось анализировать его целиком;
URI или URL метода. Состоит из одного из типовых глаголов плюс сам путь, по которому данный метод будет доступен. Про всякие best practices нейминга расскажу отдельно, в комментариях под предыдущим постом спрашивали;
Разрешения или Permissions. Если у вас есть ролевая модель и вам нужно разграничить доступ к каким-либо ресурсам среди пользователей с разными ролями - то вступает в дело данная строка таблицы. В ней нужно перечислить те роли, у которых есть доступ до данного метода;
Параметры запроса, который должны (или могут) быть переданы на вход данного метода. Т.к. у нас очень простой метод, то у нас их нет. Единственный атрибут в виде идентификатора пользователя ( ) передается напрямую в ссылке. Т.е. пример запроса будет просто выглядеть вот так: GET /users/22 - дай мне пользователя с идентификатором 22.
Пункт больше для удобства, в случае, если у вас большая система и много взаимодействующих компонентов. Описываете, кто будет дергать ваши метод. Как минимум это нужно для того, чтобы потом, когда вы будете дорабатывать их - было понятно влияние. В данном случае, если вдруг метод поменяется мажорным образом, добавится какой-нибудь новый обязательный параметр - вы не забудете доработать еще и фронт.
Параметры ответа. Все варианты того, что ваш метод вернет вызывающей стороне после выполнения своей внутренней логики. Перечисляем как успешные коды ответа и всё их содержимое, так и ошибочные.
Непосредственно описание бизнес-логики метода. Т.е. что метод должен сделать с атрибутами, переданными на вход, и что должен вернуть.
Теперь немного про описание самой логики работы любого сервиса. Кому-то может показаться это сложным, но на самом деле все немного проще. Вам просто логически нужно представить у себя в голове, что должен вообще в принципе сделать ваш метод и попытаться придумать - как он должен это сделать.
На этом примере - у вас стоит бизнесовая задача (например): есть админка со списком пользователей, администратор нажимает на какую-то конкретную карточку пользователя, с целью просмотреть всю информацию по нему - в этот момент, как раз фронт откроет отдельную экранную форму и вызывает наш метод, передавая туда идентификатор искомого пользователя (который он ранее получил из другого метода, который получает массив пользователей, что-то вроде GET /users), чтобы получить всю нужную информацию для отображения.
Далее представляем что наш метод должен сделать, чтобы вернуть информацию по этому пользователю. Самое логичное - надо сначала найти его. Для этого нужно залезть в таблицу с пользователями и найти такого пользователя, у которого идентификатор будет совпадать с тем, что нам передали в запросе. Нашли - круто, не усложняем и возвращаем успешный успех фронт с передачей в теле ответа всей необходимой информации.
А что делать если не нашли? Вообще, технически такого быть не должно, потому что это значит, что у фронта устаревшая или недостоверная информация и нужно с этим разбираться - откуда он взял идентификатор, которого не существует? Но представим, что после того как админ открыл страницу со списком пользователей и до того, как перешел в карточку конкретного - другой админ удалил ее. В этом случае надо вернуть ошибку, что такой объект не найден.
Ну и всегда (по моему мнению), во всех методах нам нужно валидировать входящий запрос до того, как начать основную бизнес логику. Потому что зачем нам это делать и тратить драгоценное время и ресурсы, если мы заранее знаем, что запрос не валиден? Т.е. как минимум нам нужно проверить rq на соответствие контракту, что все обязательные атрибуты пришли и пришли в корректном формате. Как максимум выполнить еще всякие кастомные валидации, по типу тех же проверок на роли.
Также заранее поясняю, что в ответе ссылка на объект User (пользователь) ведет на описание атрибутивного состава объекта (в моем примере в конфлю нет, потому что я этого не сделал, но на боевых задачах - да), поэтому не нужно расписывать и дублировать этот объект еще и тут. Однако, если вам нужно передать не весь объект, а только его часть, например, не возвращать на фронт какие-то пароли пользователей или другие конфиденциальные данные, чтобы их не "схачили" - то нужно отдельно это указывать.
И еще поясню немного про пункт 1.b - особенно внимательные наверняка про него что-нибудь скажут. Пока писал, подумал, что можно использовать этот метод не только для админа, но и переиспользовать его на случай, когда обычный пользователь хочет получить информацию по себе же, например, когда открывает свой профиль. Вместо того, чтобы делать отдельный метод - просто разграничиваем права. Если он захочет запросить информацию о ком-то другом (если фронт подведет), то ему вернется болт.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.

Что сподвигло меня сделать это курс по Ворду? Ведь я вместо этого мог бы сыграть в 3-4 шахматных турнирах с тщательной предварительной подготовкой. Или, вообще, плюнуть на все и уехать на дачу, копать червей для рыбалки... Дело не в том, какие дороги мы выбираем. Дело в том, что такое в нас самих заставляет нас выбрать ту или иную дорогу... Когда-то давным-давно, лет 5 тому назад, один наш программист сделал для бухгалтерии функционал, который периодически рассылал сотрудникам предупреждения о разных событиях, типа неожиданных премий и т.п. Функционал основан на шаблонах Ворда и по неизвестной причине перестал работать. Надо ремонтировать! А это оказалось не так просто, как показалось сначала.
Вызывает меня как-то зам главного бухгалтера (милая приятная женщина) и говорит трагическим голосом.
- Все пропало!
- Клиент уезжает, гипс снимают? - уточнил я.
Выяснилось следующее.
Когда-то давным-давно, лет 5 тому назад, один наш программист сделал для бухгалтерии функционал, который периодически рассылал сотрудникам предупреждения о разных событиях, типа неожиданных премий и т.п.
Примерно вот такого содержания.
"Сообщение о премии".
...
Уважаемый Иванов Иван Иванович! По итогам работы за квартал вам будет выплачена дополнительная премия в размере 30 тысяч рублей. Спасибо за отличную работу.
...
Программист, сделавший этот функционал, давно уволился, никто эту программу не поддерживал, да и потребности в этом вроде как не было. Бухгалтера нажимали нужные кнопки и все работало.
Ничто не предвещало, но все-таки это случилось. Программа перестала работать. Почему, непонятно. Документации, конечно, никакой не было. Бухгалтера начали все это делать вручную. Работа простая. Нужно сделать около сотни похожих файлов Ворда и разослать сотрудникам, попавшим на эту премию.
Один раз бухгалтера это сделали, но это им сильно не понравилось. Они хорошо помнили те славные времена, когда процесс проходил за несколько минут без всяких ошибок. Теперь они ковырялись с этими файлами больше недели, да еще сделали одну нелепую ошибку. Одному сотруднику приписали лишний ноль, т.е. 400 тысяч вместо 40. Сотрудник сначала сильно обрадовался, заранее потратил кучу денег, залез в кредит. А потом еще более сильно огорчился, когда получил реальные деньги, а не просто сообщение.
Бухгалтера поняли, что программу надо чинить и обратились к нам.
Зачем вообще нужны эти извещения? Ведь все равно получатель премии узнает о ней по факту прихода денег на карту.
Ответ простой. Это старая добрая корпоративная традиция, и не нам, разработчикам и бухгалтерам, ее ломать. Народу нравится! И этим все сказано.
Короче, взялся я за дело и через некоторое время с удивлением понял, что Ворда я не знаю, и никакие курсы, справки, сайты в Интернете мне не помогали. Вроде все просто. Есть переменная, вот она, живая, но почему-то не работает. Почему, непонятно.
Позвал на помощь товарищей по работе, устроили мозговой штурм. Залезли в жуткие вордовские дебри и с огромным трудом поймали за хвост истину.
Выяснилось следующие.
В Ворде есть переменные "старого" типа, а есть "нового" типа. Программист широко использовал и те и другие. Но они совсем разные, эти переменные. И косяки у них тоже разные. У "новых" переменных есть такая жесткая особенность, нельзя их исправлять прямо в тексте. Визуально такие исправления вроде как срабатывают, но по факту это не так. Внутри все стало работать неправильно. А чтобы увидеть дефект и исправить, надо разархивировать файл docx (а это обычный zip архив, в котором несколько файлов xml) и там уже править дефектный xml. Это уже задача не для новичков!
Или, что проще, просто с нуля аккуратно переделать файл docx непосредственно в Ворде.
Так или иначе, после того, как проблема была понята и осмысленна, решить ее было уже просто.
После того как я убедился, что этот функционал успешно работает, (я сам получил сообщение о премии), я решил сделать небольшой курс по Ворду.
Хотелось, чтобы если кто-то еще столкнется с подобными проблемами, то смог бы быстро их решить.
У меня уже был успешный опыт создания подобных курсов, например: курс по Экселю.
Почему бы не сделать еще один?
Тут я уже двигался по проторенной дорожке: текстовый курс с картинками, тщательное тестирование, путем многократного выполнения нужных действий курсанта по заданному плану, видео материалы.
Я решил подробно расписать все эти особенности, "ловушки" Ворда, чтобы сделать работу с этой программой максимально комфортной.
В итоге получилось: один длинный текст с картинками, а к нему еще примыкают 3 видео.
Идея такая. Кто-то больше любит читать тексты (как я, например), кто-то больше любит, чтобы ему показывали в видео формате.
Вот в таком виде, во всех форматах курс подойдет всем, никто не останется без нужных знаний.
Вот краткие описания основных составных частей курса.
Часть 1 - Подготовка. Запуск.
Что такое Word и кому он нужен. Запуск. Наш первый файл "Hello, Word" или "Привет, Ворд". Разметка страницы. Шрифты, настройка. Вставка картинки. Гиперссылка.
Часть 2 - Переменные "старые" и "новые". Макрос VBA.
Переменные "старого типа" и переменные "нового типа". Наш первый макрос в Ворде. Ключевые моменты макроса. Устанавливаем значения переменных.
Часть 3 - Автоматизация.
Как создать 99999 однотипных документов Ворда для приглашений на праздник клиентов и/или сотрудников, расписок работников о согласии на что-то, резюме искателя работы с указанием разных работодателей и т.п. Заключение. Лайфхаки. Ссылки. Пожелания. Развлечения.
Если есть у вас интерес быстро усвоить Word (или альтернативный редактор текстов), то добро пожаловать сюда:
Microsoft Word. Майкрософт Ворд. Курс для новичков.
Там все материалы в интуитивно понятной форме. Не требуется никакой регистрации и прочего. Просто сразу получаете нужную информацию и выполняете на практике нужные действия. Информация представлена как в виде текстов с картинками, так и в формате видео с озвучкой голосом на русском языке.
Успехов!
Полная авторская версия истории "Как я сделал курс по Ворду для новичков" здесь:
#############
### Конец ###
#############
В сфере айти я отработала столько, сколько приличные люди не живут и зарплата бывала разная, но маленькой её не назовёшь в любой период. Не то чтобы чёрная икра мазалась на крутоны с двух сторон поверх красной, но о деньгах можно было особо не думать. Плюс не только дизайнер настолько широкого профиля, что даже в объектив не влезает, а вполне себе аналитик и в программирование тоже делала на факультативной основе. Особо в эту область я не совалась, но понимать внутренний мир происходящего это сильно помогало. Потому что мало нарисовать красивую картинку, нужно ещё понимать как её на реальность натянуть без костылей.
И вот, за три года до финала головокружительной карьеры дизайнера, к нам в отдел заглянул местный директор со словами: "В Московской головной конторе доели очередного дизайнера сейчас дизайнера нет, просят из наших кого-нибудь. Матёрого и с опытом отсюда и до горизонта." Дизайнеров в Москве изводили со страшной скоростью и в промышленных масштабах. Эдакий расходный материал, за круговоротом которого мы из нашего Новосибирска наблюдали со спортивным интересом.
Начальник дизайнерского отдела задумчиво смотрел на меня, остальные дизайнеры пригнулись за мониторы. Попытка прикинуться уборщицей провалилась с треском, и со словами "это на месяц, пока нового не найдут" меня назначили дистанционно любимой женой в Москву. Выдыхаться как дизайнер я уже начинала, но отказываться от приятной зарплаты ещё была не готова. Головной офис сразу приступил к воспитанию, объяснив кто тут главный, а у кого ручки из жопки и вместо головы глиняный горшок.
Месяц превратился в два и плавно растянулся на три года. Одной рукой верстая полиграфию, второй отдизайнивая соцсети, третьей разрабатывая интерфейсы и немного залезая в 3D моделирование, я радовалась что дистанционно откусывать голову дизайнеру получается не очень эффективно. Москва кипела трудовым энтузиазмом как после окончания нашего рабочего дня, так и по выходным. Появляться на работе в чётко установленное время было не обязательно, но иное не одобрялось, отбой мог наступить уже вместе с головной конторой, разница во времени составляла четыре часа. Постепенно поверх уже накопившегося выгорания накрывало глобальным отвращением к IT в целом. Тошнило от мониторов, векторов и прочих фотошопов в сумме, но два уже не мелких, но ещё слегка несовершеннолетних дитятки дома хотели кушать и учиться.
К моменту, когда московский офис нашёл дизайнера, я выдохлась окончательно. Впрочем, того дизайнера они тоже успешно и быстро истребили, но всё уже начало накрываться глобальным коронным катаклизмом с сокращением конторы до минимальных размеров. И вот тут наступил момент, о котором я буду вспоминать как об одной из ключевых развилок в жизни. Узнав, что я осталась без дела, мне позвонила знакомая, с которой мы работали раньше и сказала что меня очень хотят видеть на должности аналитика в Сбере. Сказать что я присела от изумления на задницу, не сказать ничего. Корками о высшем образовании я так и не разжилась и вообще - где я, а где банковские системы.
"Хорошие аналитики на дороге не валяются, мы готовы вложиться в обучение." - с этими словами меня ждали на собеседовании. Времени на подумать давалось неделя, осознавая размеры зарплаты в Сбере, одновременно я понимала, что в офисе за монитором повешусь за любую зарплату и очень быстро. Логически взвешивать "за" и "против" не имело смысла - такие предложения с неба пачками не падают и на дороге не валяются. Отловив бывшего мужа, работающего в Сбере начальником одного из IT-отделов, я крепко взяла его за пуговицу пиджака и изложила факты. Он не удивился, времени привыкнуть к неожиданным манёврам в моей жизни у него было предостаточно.
Отговаривать или убеждать он не стал, но кратко изложил суть работы. Общались мы регулярно, его график и нагрузки я знала, и вполне могла представить, что будет. Дети уже подходили к совершеннолетию, по моим понятиям после этого подножный корм им следовало добывать самим, с моей поддержкой на стартовом этапе. Небольшая подушка безопасности имелась, но понимания чего я хочу не было абсолютно. Но при одной мысли о том, чтобы снова двинуть в сферу IT в любом качестве, в душе поднимался яростный протест и понимание, что лучше застрелиться сразу.
Только идиоты отказываются от таких предложений, я была идиотом и сделала шаг от тёплого и очень сытного офиса в никуда. Понимала ли я от чего отказываюсь? Однозначно да. Знала ли, что ждёт впереди? Нет. Там ждали пара-тройка лет с местами полуголодным существованием, дети выросли окончательно и отправились искать своё пастбище, а я пыталась найти своё место вне IT, абсолютно не представляя где оно. Пожалела ли о принятом тогда решении? Ни разу. Я фрилансила, варила пиво, сыр, делала конфеты, и даже работала продавцом в разливайке, пока не наткнулась на кратко промелькнувшее "требуются продавцы-консультанты в секс-шоп".
Наверное, тут должно быть писец какой мотивирующий финал с призывом выйти из зоны комфорта и побежать по просторам, вдыхая ветер свободы и распевая чакрами. Но мы же тут все взрослые люди и понимаем, что ветер свободы в реальном мире вполне может оказаться полной жопой. Было время безнадёги, сменяясь временем подъёмов. Был приобретён вагон навыков, которые не появляются в той самой зоне комфорта, просто потому там что нет смысла морщить мозг и выкручиваться. В секс-шопе меня иногда удивляет то, что это считают работой, потому что мне реально в кайф, а в свободное время я могу заниматься своими проектами, которые тоже приносят немало удовольствия. И, как я надеюсь, будут удачными в материальном плане. Бэкграунд, приобретённый путём лихих прыжков по граблям за этот период для меня бесценен, хоть и дался немалым трудом.
P.S. Для интересующихся, как могла здравомыслящая мать обречь малышей на такой дауншифтинг, отвечу - на них платились алименты, предусмотрительно частично откладываемые и присоединённые к тому, что отложила сама. Этого хватило какое-то на время даже после их совершеннолетия, пока они талантливо валяли дурака, то принимаясь учиться, то бросая эту затею. Экономила я лично на себе, пока не выгребла из смутного времени неопределённости.

С момента запуска проекта FreeBSD прошло 30 лет. Официальный портал данной инициативы напомнил, что 19 июня 1993 года в Калифорнийском университете в Беркли представили операционную систему с открытым кодом, которая стала основой для многих некоммерческих и бизнес-решений.
Отсчёт идёт с момента создания форка 4.3BSD на основе неофициального набора исправлений к 386BSD, который был предназначен для разработки быстрой и устойчивой к безопасности операционной системы для машин с процессорами i386.
В своих прошлых и нынешних итерациях FreeBSD может похвастаться множеством дополнительных библиотек и инструментов, которые постоянно улучшаются на протяжении долгих лет. Специалисты уверены, что долговечность FreeBSD обеспечивается благодаря BSD license (Berkeley Software Distribution license) — лицензией с открытым кодом, которая позволяет свободно распространять программное обеспечение.
Всем привет.
Настала пора наконец закончить с прелюдиями и перейти к рассказу про один из самых важных навыков системного аналитика - REST. Больше важны навыки практического применения\проектирования, но и теория тоже важна. Как минимум для прохождения собеседования, потому что значительная часть вопросов приходится как раз на интеграцию и знание REST в том числе.
В следующем посте разбавлю серию только теоретических - практикой. Приведу шаблон того, как можно описывать API.
REST
Representational State Transfer (REST) в переводе — это передача состояния представления.
Сам по себе REST – это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
И у него есть определенные принципы, которые важно понимать и применять при проектировании системы.
В рамках данного принципа самое важное - это отделение клиента и сервера. Клиент - это интерфейсная часть (уровень представления), сервер - это центральное звено системы, на котором реализованы все основные функции системы (наш backend). Более подробно рассмотрено в части 6 этой серии.
Это понятие означает, что сервер не должен хранить информацию о состоянии клиента, в том числе информацию о предыдущих запросах клиента, а клиент не должен знать ничего о текущем состоянии сервера.
Это не значит, что у них вообще нет состояния, но они не отслеживают состояние друг друга (что очень удобно, т.к. избавляет нас от необходимости держать постоянное неразрывное соединение между двумя системами).
Поэтому каждый запрос рассматривается индивидуально, как будто бы не было ничего до, и не будет после. Соответственно клиент в этом случае, обязан предоставить все необходимые данные для успешного выполнения запроса. Это, пожалуй, почти единственная логика, которая должна быть на клиенте.
Принцип гарантирует, что между клиентом и сервером существует общий язык (интерфейс), с помощью которого они будут понимать друг друга. Т.е. клиент посылает понятные серверу запросы, использую конкретные HTTP-методы, сервер посылает ответ в понятном клиенту формате.
Это достигается через несколько субограничений:
Идентификация ресурсов
В терминологии REST что угодно может быть ресурсом — HTML-документ, изображение, информация о конкретном пользователе - то, чему можно дать имя. Каждый ресурс должен быть уникально обозначен постоянным идентификатором. «Постоянный» означает, что идентификатор не изменится за время обмена данными, и даже когда изменится состояние ресурса. Если ресурсу присваивается другой идентификатор, сервер должен сообщить клиенту, что запрос был неудачным и дать ссылку на новый адрес.
Тут важно понимать, что в REST (в идеале, по крайней мере), ресурс может быть только существительным, а не глаголом. Потому что за "глагол", т.е. действие - отвечает конкретный метод.
2. Управление ресурсами через представления
Второе субограничение «унифицированного интерфейса» говорит, что клиент управляет ресурсами, направляя серверу представления, обычно в виде JSON-объекта, содержащего контент, который он хотел бы добавить, удалить или изменить. В REST у сервера полный контроль над ресурсами, и он отвечает за любые изменения.
Когда клиент хочет внести изменения в ресурсы, он посылает серверу представление того, каким он видит итоговый ресурс (а для этого, сервер сначала должен предоставить эту информацию клиенту). Сервер принимает запрос как предложение, но за ним всё так же остаётся полный контроль.
3. Самодостаточные сообщения
Самодостаточные сообщения — это ещё одно ограничение, которое гарантирует унифицированность интерфейса у клиентов и серверов. Только самодостаточное сообщение содержит всю информацию, которая необходима для понимания его получателем. В отдельной документации или другом сообщении не должно быть дополнительной информации.
В данных запроса должно быть указано, нужно ли кэшировать данные (сохранять в специальном буфере для частых запросов). Если такое указание есть, клиент получит право обращаться к этому буферу при необходимости.
Это нужно для того, что максимально ускорить обработку запроса от клиента. Для примера, если нам нужно часто получать информацию о пользователе (а сама информация о пользователе меняется достаточно редко, что важно), то мы можем закэшировать эту информацию.
Т.е. стандартный запрос выглядит условно так: Фронт -> микросервис адаптер к фронту -> какой-нибудь микросервис MDM системы пользователей -> база где лежат пользователи и потом обратный путь. Это не прям мгновенно всё происходит. Что мы делаем - например, наш фронт прислал запрос GET /user/121, мы проделали этот путь, описанный выше, но еще и сохранили эти данные в кэше на уровне микросервиса-адаптера. В следующий раз, когда фронт вызовет метод GET /user/121, наш путь будет намного короче и быстрее - всего лишь от фронта к нашему же микросервису в кэш и сразу обратно.
Тут есть множество нюансов, которые нужно учесть - но в целом полезный инструмент.
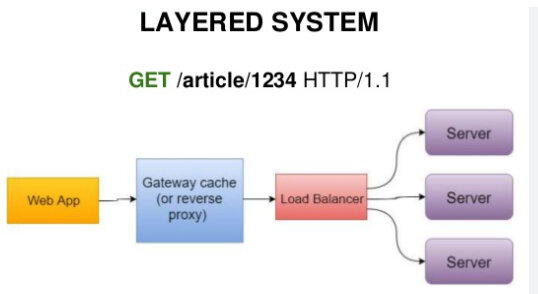
Система слоев предполагает наличие большего количества компонентов, чем клиент и сервер. В системе может быть больше одного слоя. Тем не менее, каждый компонент ограничен способностью видеть только соседний слой и взаимодействовать только с ним.
Но что самое замечательное, при добавлении новых слоев между клиентом и сервером - их не нужно дорабатывать. Т.е. не важно, если у нас архитектура выглядит как просто "Клиент" -> "Сервер", или "Клиент" -> "Прокси" -> "Балансировщик" -> "Несколько серверов" - их логика не меняется (тут разработчики могут меня поправить или дополнить, буду благодарен).
Что-то вроде того:
Еще есть отдельный принцип "Код по требованию", который подразумевает то, что клиент может получить с сервера прям "кусок кода" (условно), который ему необходимо выполнить у себя.
Звучит интересно, но честно, ни разу не сталкивался, поэтому не могу что-то детальное рассказать.
P.S.: В следующих постах расскажу про best practices, связанных с именованием эндпоинтов и прочими полезными штуками для проектирования своих апишек.
По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
В прошлом посте рассказал про HTTP в целом и много раз упоминал различные методы, но еще не рассказал что это такое - разбираемся.
Как я уже писал, метод - это название запроса, которое определяет то действие, которое будет совершаться в результате его выполнения.
Их всего 6 основных:
Метод GET предназначен для получения информации о каком-то конкретном ресурсе или массиве ресурсов. Он никак не изменяет эту информацию.
Похож на GET, но не возвращает тело ответа, а только стартовую строку и заголовки. Используется для получения метаданных, а также проверки и валидации ресурса.
Честно говоря - ни разу не приходилось использовать его на практике или даже просто видеть. Но могу предположить, что его можно использовать в том случае, когда нам нужно ткнуть какой-то ресурс палочкой и спросить - а ты вообще существуешь? Ну и, возможно, получить по нему какую-то метаинформацию.
Условно, можно вызвать HEAD /users/127 - мы получим в ответе HTTP 200, в том случае, если этот пользователь с идентификатором = 127 существует. И 404 - если нет.
Если же вызвать GET /users/127 - то мы получим HTTP 200 + тело ответа, в котором будет содержаться вся информации о пользователе с идентификатором 127 (ну тут смотря как реализовать, но по дефолту будет так).
Создает новый ресурс из переданных данных в запросе. Но это лишь по дефолту.
На самом деле POST самый универсальный метод и им возможно делать всё - и получать информацию, и создавать, и редактировать, и удалять, и запускать какие-то процессы. Тут важно понимать - почему именно так.
Например, мы можем использовать POST для поиска в том случае, если нам нужно зашифровать поисковые параметры в теле запроса, а не оставлять их в открытом виде в query-параметрах (прям в строке запроса). Либо использовать для поиска в том случае, если поисковых параметров слишком много и строка запроса получается слишком огромной - а у нее есть определенное ограничение по длине (очень больше, но всё-таки есть).
Можно использовать для запуска различных команд в оркеструющих микросервисах или коммандерах. Т.е. напрямую у нас никакой объект не создается, физических и лежащий в БД - но у нас создается (запускается) какой-нибудь бизнес-процесс.
Применений у этого метода очень много.
Изменяет содержимое ресурса по-указанному URI. PUT полностью заменяет существующую сущность.
Похож на PUT, но применяется только к фрагменту ресурса (заменяет точечно только часть ресурса)
Для понимания: Например, у вас есть объект user, у которого 5 атрибутов - Ф, И, О, дата рождения и пол. Если у вас поменялась информация о пользователе №5, например изменилась фамилия - и вы вызовете метод PUT /users/5, и передадите в теле запроса только фамилию, то на выходе у вас останется объект user с id = 5, и фамилией = тому, что вы передали в запросе. Все остальные атрибуты затрутся. Поэтому для обновления необходимо передавать все объект целиком, включая те атрибуты, которые не менялись.
Если же вы вызовете метод PATCH /users/5 с таким же запросом, то у вас обновится только фамилия, остальной объект останется не тронутым.
Логичный вопрос - а зачем тогда вообще использовать PUT? Ответ достаточно простой - он намного проще в реализации. Куда проще передать объект целиком ценой нескольких байт трафика и подменить его, чем обновлять каждый атрибут по отдельности, маппить их и т.д. Особенно если у вас какой-нибудь огромный объект, типа "Заявка на кредит", у которой под тысячу атрибутов, а вам нужно обновить 200 из них.
Тут разработчики могут меня поправить, но объясняли мне в свое время так.
Удаляет конкретный ресурс по-указанному URI.
Интересное: на самом деле нет никаких проблем с тем, чтобы заставить метод GET создавать какой-нибудь ресурс или заставить метод DELETE обновлять. Т.е. это не технические ограничение, это "лишь" концептуальная идеология того, как правильно (и для чего) использовать различные методы.
Чтобы на всех проектах, все участники разработки были в едином контексте. И когда вы будете видеть какой-нибудь метод, типа POST /loanApplication//offers - вы явно поймете, что это метод предназначенный для добавления новых офферов конкретной заявке на кредит.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.